27 de maio de 2026
| # | Modelo | Score | Δ | |
|---|---|---|---|---|
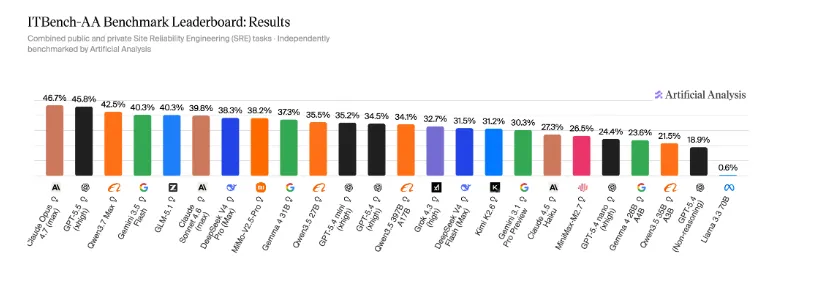
| 01 | Claude Opus 4.7 (Adaptive Reasoning, Max Effort) | 47% | — | |
| 02 | GPT-5.5 (xhigh) | 46% | — | |
| 03 | Qwen3.7 Max | 42% | — | |
| 04 | GLM-5.1 (Reasoning) | 40% | — | |
| 05 | Gemini 3.5 Flash (high) | 40% | — | |
| 06 | DeepSeek V4 Pro (Reasoning, Max Effort) | 38% | — | |
| 07 | Gemma 4 31B (Reasoning) | 37% | — | |
| 08 | Gemini 3.1 Pro Preview | 30% | — |
A primeira rodada do ITBench-AA SRE estabelece um novo patamar para benchmarks de tarefas agentic em TI corporativo. Lançado em parceria entre Artificial Analysis e IBM Research, o teste avalia a capacidade de LLMs e agentes em diagnosticar incidentes complexos em ambientes Kubernetes — um cenário crítico para operações de site reliability engineering (SRE).
Como funciona o ITBench-AA
O benchmark cobre 59 tarefas de SRE, das quais 40 são públicas e 19 inéditas, com snapshots de incidentes Kubernetes que incluem alertas, eventos, logs, traces, métricas e topologia de aplicações. O desafio: identificar o conjunto mínimo de entidades Kubernetes responsáveis por cada incidente, com falhas que vão de esgotamento de recursos a políticas de rede bloqueando serviços.
Os modelos rodam no harness open-source Stirrup, com acesso shell a um sistema de arquivos sandbox contendo todos os dados do incidente. Cada tarefa permite até 100 turnos e é repetida três vezes por modelo. O score segue uma métrica rigorosa: só são contabilizados casos em que todos os root causes são identificados; qualquer entidade extra é penalizada como falso positivo. O resultado final é a média das execuções.
Desempenho dos modelos
Nenhum modelo frontier superou a barreira dos 50%. O Claude Opus 4.7 (Adaptive Reasoning, Max Effort) liderou com 47%, seguido de perto pelo GPT-5.5 (xhigh) com 46% e Qwen3.7 Max com 42%. Entre os open weights, GLM-5.1 (Reasoning) e Gemini 3.5 Flash (high) empataram em 40%, enquanto DeepSeek V4 Pro (Reasoning, Max Effort) chegou a 38% e Gemma 4 31B (Reasoning) a 37%. O Gemini 3.1 Pro Preview ficou em 30%.
A variação no número de turnos é notável — GPT-5.5 (xhigh) usa em média 31 turnos por tarefa, enquanto Gemini 3.1 Pro Preview chega a 83. Modelos que “over-investigam” tendem a apontar sintomas ou mecanismos de falha upstream como causas, perdendo pontos por precisão. O benchmark mostra que trajetórias mais longas não garantem melhor acurácia.
Custo por tarefa
O ITBench-AA também compara o custo por tarefa: Gemma 4 31B (Reasoning) entrega 37% de score por US$ 0,14, superando Gemini 3.1 Pro Preview (30%, US$ 2,23) em eficiência. Claude Opus 4.7 lidera em acurácia, mas é o mais caro, a US$ 5,38 por tarefa.
O que diferencia o ITBench-AA
Ao exigir diagnóstico preciso de root causes em incidentes reais e penalizar respostas prolixas, o ITBench-AA se posiciona como um dos benchmarks agentic menos saturados do mercado. Para comparação, os mesmos modelos apresentam scores bem mais altos no Terminal-Bench, sugerindo que tarefas de SRE representam um desafio distinto e ainda não dominado pelos LLMs atuais.
Referências técnicas
A metodologia e o dataset são detalhados no paper oficial no arXiv. O leaderboard completo está disponível em artificialanalysis.ai, e o código-fonte do harness Stirrup e do dataset pode ser consultado no GitHub do ITBench.
Para quem importa
O ITBench-AA SRE é referência para equipes de MLOps, SRE e pesquisa que buscam avaliar modelos em cenários próximos da produção. O baixo desempenho geral indica que automação agentic em incidentes complexos de TI ainda está longe do ponto ótimo — e diferenciações relevantes entre modelos já aparecem em custo, precisão e estilo investigativo.