LLMs ainda falham em probabilidade contraintuitiva, diz novo benchmark
Estudo testa 8 LLMs em problemas clássicos e contraintuitivos de probabilidade. Precisão cai de 96% para 59% em exercícios que desafiam heurísticas.
Medições, comparações e dados sobre capacidade dos modelos.
17 edições arquivadas
Estudo testa 8 LLMs em problemas clássicos e contraintuitivos de probabilidade. Precisão cai de 96% para 59% em exercícios que desafiam heurísticas.
Novo método Code2LoRA usa hypernetworks para gerar adapters LoRA específicos por repositório, superando abordagens tradicionais em benchmark com 604 projetos Python.
OpAI-Bench propõe avaliação inédita da detecção de autoria IA em textos editados por humanos e IA, analisando granularidades de documento a token e revelando padrões não monotônicos.
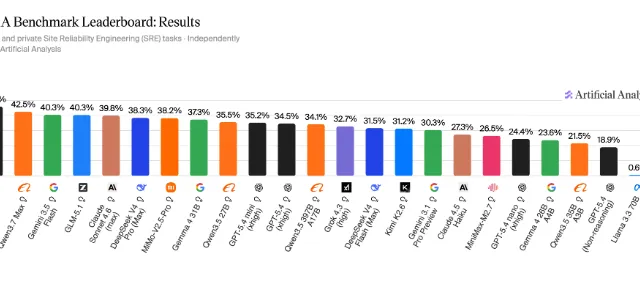
Novo ambiente ClinEnv mede como LLMs atuam como médicos em cenários reais de internação, avaliando tanto decisões quanto o processo de coleta de informações.
Estudo mostra que LLMs open-source de porte médio conseguem captar semântica de construções raras como 'let alone', sugerindo avanço além da mera sintaxe.
Novo benchmark PEFT-Arena mede trade-off entre adaptação e retenção em técnicas de finetuning eficiente. Análise mostra vantagens do orthogonal finetuning.
Primeira rodada do ITBench-AA avalia LLMs em diagnósticos complexos de Kubernetes. Nenhum modelo supera 47%. Claude Opus 4.7 lidera, seguido por GPT-5.5 e Qwen3.7.
Estudo testa seis chatbots comerciais em 2.100 perguntas factuais de notícias BBC. Líderes atingem 90% de acerto, mas desempenho cai para idiomas não-ingleses e questões com premissas falsas.
Benchmark de maio mostra modelo de 3B parâmetros da DharmaAI vencendo Claude, GPT-5 e Google Vision em OCR estruturado de documentos brasileiros, com custo operacional 52 vezes menor.
Novo benchmark FutureSim testa agentes de IA em previsões de notícias reais, simulando eventos entre janeiro e março de 2026 e revelando limitações nas capacidades de adaptação.
Benchmark compara grep e retrieval vetorial em workflows agenticos com LLMs. Grep tem desempenho superior, mas resultado depende do harness e estilo de chamada de ferramenta.
EVA-Bench propõe avaliação de ponta a ponta para agentes de voz, com métricas inéditas de precisão e experiência. Framework cobre 213 cenários e três arquiteturas.
Novo levantamento Gallup mostra que jovens americanos estagnaram no uso de IA, ampliaram desconfiança e preferem serviços humanos, mesmo reconhecendo ganhos de produtividade.
Avaliação do Deep Agents mostra GLM-5 e MiniMax M2.7 próximos de Claude Opus 4.6 e Gemini 3.1 Pro em file ops, tool use e instruções, com custos menores.
Novo método formaliza auditorias comparativas de segurança para LLMs mesmo sem benchmarks rotulados. Estudo de caso com modelos Borealis e Gemma 3.
Estudo mostra que LLMs trazem sinais internos de gramaticalidade, superando a simples probabilidade de string em benchmarks de julgamento gramatical.
Estudo com 14 LLMs mostra queda brusca de acurácia ao executar algoritmos aritméticos extensos. Desempenho cai de 61% para 20% em tarefas com até 95 etapas.